Alfabeto morse internacional, letras, números, signos, espaciado
Repasando el bosquejo sobre la evolución de la telegrafía eléctrica, el alfabeto morse que terminó por estandarizarse a nivel mundial fué el internacional representado aquí, a su vez derivado del antiguo código morse original conocido hoy como americano. La idea original de Samuel Morse fue la de un código compuesto únicamente por números y un libro de claves para transcribir luego a caracteres. Además la idea de Morse era la de que los mensajes se debían decodificar sin la intervención del operador mediante el impresor, algo que en poco tiempo terminaron haciendo los propios operadores a oído.
Sin embargo este sistema numérico resultó excesivamente tedioso y sujeto a errores por lo que su estrecho colaborador, Alfred Vail, ideó el primer código alfanumérico con un trabajo de documentación en un periódico local sobre las letras estadísticamente más usadas. Así, a la letra "e", por ejemplo, se le asignó la estructura más sencilla, el punto (pulso o señal corta), por ser el caracter más habitual en inglés, etc.

En este primer código predominaban sobre todo los puntos o pulsos cortos y resultaba ser de un 5% a un 20% más rápido que el internacional (una modificación posterior), pero algo extraño desde el punto de vista actual porque algunos caracteres incluían espaciados internos y diferentes duraciones de pulsos largos. Esto hacía que el dominio del código por parte de los operadores, tanto para la recepción como para la transmisión, requiriese de bastante maestría porque era muy propenso a errores. Supuso una radical ventaja y mejora con respecto a la idea del código numérico de Samuel Morse. Sigue siendo a día de hoy objeto de debate y discusión sobre quién creó esta estructura alfanumérica pero existe documentación suficiente para atribuir a Vail la invención del primer código aunque su nombre y autoría cayesen en el olvido.
Con el éxito y la rápida expansión del morse, surgieron variantes en muchos países pero la más importante fué la del alemán Friedrich Clemens Gerke que en 1848, inicialmente solo usada en la línea telegráfica entre Hamburgo y Cuxhaven, reorganizó y cambió cerca de la mitad del alfabeto y todos los números dando lugar al código continental o "Alfabeto de Hamburgo" que se aprobó como estándar en el Congreso Internacional de Telegrafía de París en 1865. Con esta modificación, Gerke eliminó la complejidad que suponía la existencia de los espaciados internos especiales y las diferentes duraciones de los pulsos largos o rayas en algunos caracteres del morse original, unificando el código que ya solo estaría compuesto por dos elementos.

El morse original pasó a llamarse morse americano o railroad morse para diferenciarlo del continental o internacional y continuó usándose durante varios años en telegrafía terrestre en todo el continente americano hasta su progresivo desuso siendo uno de sus últimos reductos la red de ferrocarriles mexicanos y en general los países de Centro y Sudamérica.

Con la coexistencia de los dos formatos, mezcla y a veces confusión entre operadores, se terminó por establecer una última y definitiva variación, el código internacional, aprobado en 1912 en Londres y en adelante por la recién creada ITU en 1932 en Madrid, al fundirse las dos organizaciones internacionales existentes, la Unión Telegráfica y la Unión Radiotelegráfica.
A pesar del establecimiento del código internacional, el morse original o americano siguió utilizandose a veces de manera exclusiva en algunos ámbitos y países del continente americano hasta casi finales de la década de los años 1990, es decir hasta el último momento de la desaparición de la telegrafía oficial o comercial.
Existen muchos otros alfabetos alternativos como el japonés wabun o código kana (oubun es el internacional para los nipones), el chino, el coreano o skats, otras variantes orientales, griego, ruso, árabe, turco, etc. Además, dependiendo del idioma, existen caracteres con tildes, especialmente vocales, ampliamente usados aunque no figuren en la actual especificación internacional, y que normalmente suelen reemplazarse por la variante sin tilde a fin de simplificar.

El código morse no diferencia entre mayúsculas y minúsculas por motivos obvios de simplicidad y abreviación; aparte de la copia a mano donde es indiferente si escribimos en cualquier estilo, los mensajes, telegramas y radiogramas se han representado tradicionalmente en mayúsculas. De hecho uno de los métodos más extendidos entre los operadores más entrenados en los tiempos de gran actividad radiotelegráfica, fue el uso simultáneo de la recepción con auriculares y la escritura del mensaje en máquinas de escribir fabricadas con tipos (letras) exclusivamente en mayúsculas como, por ejemplo, las famosas "mills" que solo incluían letras mayúsculas, números con el cero barrado y únicamente los sígnos de puntuación más importantes.
No se trata en realidad de un juego de caracteres como lo entendemos en la actualidad sino más bien la asignación de un patrón a cada símbolo (traducidos luego a tonos, golpes, luz, etc.) Recordar que los puntos y las rayas son solo una representación gráfica para en principio entender la lógica, debemos centrarnos en captar y entender el sonido y la cadencia única de cada caracter con sus pulsos cortos, largos y espaciados.
[ Alfabeto morse internacional ]


 En este ejercicio de caracteres puedes practicar con el alfabeto morse desde velocidades bajas
como entrenamiento para empezar a asociar caracteres y sonidos.
En este ejercicio de caracteres puedes practicar con el alfabeto morse desde velocidades bajas
como entrenamiento para empezar a asociar caracteres y sonidos.
 En la página abreviaturas puedes encontrar además las señales de error, cambio, fin de transmisión, fin de
contacto, recibido, repite, etc. y que, sin formar parte del alfabeto morse internacional, se trata de señales
únicas o combinaciones de caracteres fundamentales para establecer comunicaciones.
En la página abreviaturas puedes encontrar además las señales de error, cambio, fin de transmisión, fin de
contacto, recibido, repite, etc. y que, sin formar parte del alfabeto morse internacional, se trata de señales
únicas o combinaciones de caracteres fundamentales para establecer comunicaciones.
Espaciado y ritmo
Sea cual sea la velocidad empleada, en el código morse la unidad o elemento básico de mínima duración es el punto o pulso-señal corta, que definirá todos los demás. La estructura básica del espaciado del código morse con la que podríamos partir para conseguir un equilibrio armonioso sería aproximadamente la siguiente:
- La duración de un punto o señal corta será de (1) UNA UNIDAD de la que derivarán las demás.
- La duración de una raya o señal larga será de (3) TRES UNIDADES.
- La duración de la ausencia de señal entre impulsos será de (1) UNA UNIDAD. (separación entre los pulsos que forman un caracter, puntos o rayas).
- La duración de la ausencia de señal entre caracteres será de (3) TRES UNIDADES (separación entre caracteres).
- La duración de la ausencia de señal entre palabras será de (7) SIETE UNIDADES (separación entre palabras).
Esta proporción puede variar ligeramente al enviar código de forma manual, los pulsos largos pueden ser algo más extensos que otros o los espaciados podrían variar, pero esto es algo intrínseco y característico en el morse, además de ser uno de los mayores atractivos de la telegrafía. Ninguna persona manipulará exactamente igual y pueden notarse grandes diferencias entre una y otra, pero si los caracteres están bien formados y el espaciado es correcto, el código resultante sonará bien en todos los casos y se podrá decodificar con comodidad. Al contrario, si no se controla armoniosamente el ritmo y el espaciado, se producirán caracteres rotos en otros dos, sonidos de caracteres que se unirán con otros, sonidos irreconocibles y confusión en general.
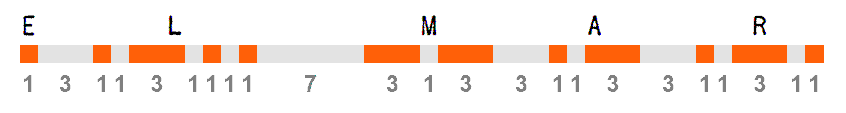
Siguiendo el texto de ejemplo y con un espaciado de proporciones correctas, sonaría así (cada vez que pulses sonará a velocidades y tonos diferentes):
Sin embargo, si no respetamos el espaciado necesario entre pulsos, caracteres y palabras, ni tampoco cuidamos la duración de los pulsos, permitiendo que todo se entremezcle, el resultado podría ser algo parecido a esto (el texto contiene todos los pulsos, cortos y largos, pero el espaciado es incorrecto):
Al decodificar este último ejemplo podríamos entender cosas como ELMAR, EL M+, EL QR, E LMAR, E LMIR, ELM IR, EAI GTR, ID QR, UI GC, etc, o no entender en absoluto algunos caracteres, por eso es tan importante llevar el ritmo y utilizar correctamente los espacios, las separaciones, que es lo que dará sentido en la decodificación. Precisamente, uno de los errores más comunes, y que termina por convertirse en un mal hábito, consiste en no separar ninguna palabra. Es de vital importancia a la hora de enviar código el tratar los espaciados como si realmente estuviéramos enviándolos, porque de hecho se tienen que enviar (hacer las pausas correspondientes entre elementos, caracteres y palabras).
Unidades de tiempo: en la siguiente tabla de caracteres puedes comprobar las unidades de tiempo de cada uno de ellos en la columna "Unidades de tiempo". Para ello se cuentan todos los elementos de tiempo, es decir, pulsos cortos o puntos (1 unidad), pulsos largos o rayas (3 unidades) y espacio entre pulsos (1 unidad). Puedes ordenar las columnas en orden ascendente o descendente.
Diagrama, agrupamientos, progresiones
Los gráficos, tablas, diagramas, representaciones, mnemotécnicos, dicotómicos, etc. son útiles en un primer acercamiento para comprender la composición y lógica del código pero en la práctica, una vez entendidos, hay que obviarlos porque dificultan el proceso más importante en el aprendizaje del morse que es el reconocimiento instantáneo de cada caracter por su sonido sin que interfiera ningún otro proceso visual o mental.
Diagrama binario (código morse internacional + Ñ):
Como curiosidad, incluso sin conocer el morse, escuchando la secuencia de pulsos y mediante el diagrama mostrado abajo, podemos averiguar de qué caracter se trata. Partiendo desde "inicio" y siempre descendiendo, si escuchamos un punto o pulso corto apuntaremos hacia la casilla más próxima a la inferior izquierda. Si escuchamos una raya o pulso largo lo haremos hacia la más inmediata a la inferior derecha. Así sucesivamente con los siguientes elementos o pulsos hasta terminar concluyendo con el caracter en cuestión. Por ejemplo, si escuchamos .--. seguiríamos una línea imaginaria que pasaría por inicio > E > A > W > P (o bien inicio > izquierda > derecha > derecha > izquierda)
| E | T | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| I | A | N | M | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| S | U | R | W | D | K | G | O | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| H | V | F | · | L | · | P | J | B | X | C | Y | Z | Q | · | · | ||||||||||||||||||||||||||||||||||||||||||||||||
| 5 | 4 | · | 3 | · | ¿ | · | 2 | & | · | + | · | · | · | · | 1 | 6 | = | / | · | · | · | ( | · | 7 | · | · | Ñ | 8 | · | 9 | 0 | ||||||||||||||||||||||||||||||||
| · | · | · | · | · | · | · | · | · | · | · | · | ? | · | · | · | · | · | " | · | · | . | · | · | · | · | @ | · | · | · | ' | · | · | - | · | · | · | · | · | · | · | · | ; | ! | · | ) | · | · | · | · | · | , | · | · | · | · | : | · | · | · | · | · | · | · |
En el código morse el número de elementos (puntos-pulsos cortos o rayas-pulsos largos) que forman cada caracter variará desde uno hasta seis, incluso más en el caso de caracteres no incluidos en la especificación internacional o estándar. En este sentido el código originalmente se concibió para que los caracteres más frecuentes (en inglés) tuviesen la menor cantidad de pulsos posible:
Otras progresiones:
Caracteres espejo: (parejas de caracteres cuyos elementos se invierten)
Caracteres opuestos: (parejas de caracteres cuyos elementos se contraponen)
Velocidad
La forma más usual de medir la velocidad en morse es en palabras por minuto o ppm, tomando como palabra una que contenga cinco caracteres. En realidad se trata siempre de velocidad media puesto que en morse unos caracteres serán siempre mucho mas largos que otros. También se puede medir mediante caracteres por minuto cpm.
Tradicionalmente a la hora de calibrar la velocidad de transmisión en ppm (o wpm en inglés) se usa la palabra estándar "PARIS" que transmitida consecutivamente con su espaciado (entre pulsos, caracteres y palabras) nos da una media general de la velocidad. Es la palabra más usada para medir velocidades medias cuando se usa lenguaje normal en claro por su equilibrio en pulsos cortos y largos.
La otra palabra estándar es "CODEX", con otro equilibrio entre pulsos, y que se usa más bien para medir velocidad media cuando se trata de grupos de caracteres aleatorios, números, signos de puntuación o mezcla de ellos.
Una forma menos frecuente de medir la velocidad es especificando la duración del elemento mínimo (el punto o pulso corto) pero igualmente tendríamos palabras con diferente número de caracteres y caracteres más largos que otros.
Tomando como ejemplo la palabra "PARIS" que consta de 50 elementos (entre pulsos cortos, largos, espacios y espaciado final entre pablabras), la duración de cada elemento vendría determinada por la fórmula: T = 1200 / P (donde T es la duración de cada elemento en milisegundos y P es la velocidad en ppm).
En definitiva, la medición de la velocidad es siempre relativa, cambia a medida que se manipula y se envía el codigo y solo se puede establecer en una media aproximada.
Para hacernos una idea de la relación entre los elementos del código cuando cambiamos la velocidad podemos variar el deslizador de lento a rápido y comprobar los valores en la siguiente simulación:
| Lento | Rápido |
| Palabras por minuto: | 20 ppm |
| Caracteres por minuto: | 100 cpm |
| Caracteres por segundo: | 1.7 cps |
| Punto (pulso corto): | 60 ms |
| Raya (pulso largo): 60 x 3 | 180 ms |
| Espaciado entre caracteres: 60 x 3 | 180 ms |
| Espaciado entre palabras: 60 x 7 | 420 ms |
| ms: milisegundos | |
Oscilador  decodificador para prácticas
decodificador para prácticas


